
{kind=link}

Parmi les différences entre les synthétiseurs, les plus pertinentes sont celles liées au modèle ou au type de synthèse, car elles affectent le cœur du processus de création, de manipulation et de reproduction du son. Il existe de nombreux types de synthèse différents, bien que la plupart d’entre eux soient minoritaires, car en termes généraux, les plus courants (qui couvrent au moins 95% des modèles) sont les suivants :
- Synthèse soustractive
- synthèse additive
- Synthèse par modulation de fréquence
- Synthèse par table d’ondes
- Synthèse par modélisation physique
Parmi eux, le plus grand nombre serait inclus dans les catégories de la synthèse soustractive et de la synthèse par table d’ondes (et cette dernière est devenue, dans de nombreux cas, une évolution de la première).
La synthèse soustractive
 La synthèse soustractive est sans aucun doute le schéma de synthèse le plus largement répandu. Presque tous les synthétiseurs analogiques et un grand nombre de synthétiseurs numériques entrent dans cette catégorie. L’idée principale (d’où le nom) est que le son est formé par la soustraction ou l’élimination d’une partie des harmoniques du générateur sonore principal. Pour faire une analogie, cela serait similaire au processus utilisé par un sculpteur qui, à partir d’un bloc de marbre, enlève une partie du matériau pour le façonner de la manière désirée.
La synthèse soustractive est sans aucun doute le schéma de synthèse le plus largement répandu. Presque tous les synthétiseurs analogiques et un grand nombre de synthétiseurs numériques entrent dans cette catégorie. L’idée principale (d’où le nom) est que le son est formé par la soustraction ou l’élimination d’une partie des harmoniques du générateur sonore principal. Pour faire une analogie, cela serait similaire au processus utilisé par un sculpteur qui, à partir d’un bloc de marbre, enlève une partie du matériau pour le façonner de la manière désirée.
Maintenant, nous allons examiner ce qui pourrait être considéré comme « le modèle de base de la synthèse soustractive ». Certains synthétiseurs s’inscriraient parfaitement dans ce modèle, bien que de nombreux autres soient en réalité des évolutions ou des sophistications de ce schéma de base, afin de fournir plus de flexibilité et de possibilités dans le processus de création sonore. Nous aborderons également certaines de ces sophistications plus tard.
Dans le modèle de base, la synthèse sonore implique quatre éléments fondamentaux : l’oscillateur, le filtre, l’amplificateur et l’oscillateur basse fréquence (LFO). Un signal est généré par l’oscillateur (qui est la source sonore proprement dite), puis il est manipulé par le filtre et enfin traité par l’amplificateur, qui peut le façonner de manière dynamique. L’oscillateur basse fréquence, en revanche, est généralement un élément qui peut être acheminé à volonté vers un ou plusieurs autres éléments (le filtre, l’oscillateur ou l’amplificateur) pour les manipuler de manière cyclique.
Le schéma ressemblerait donc à ceci :
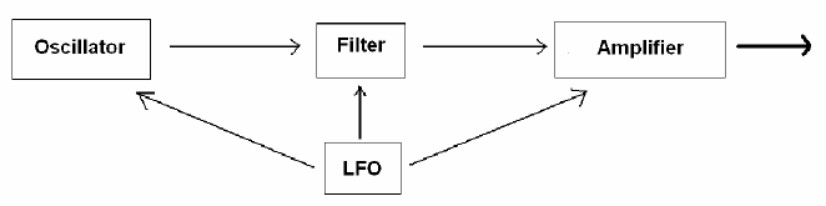
La synthèse additive
La synthèse additive, contrairement à la synthèse soustractive, fonctionne selon un principe opposé, bien que les résultats puissent être assez similaires. Alors que, dans la synthèse soustractive, le principe de base est l’élimination des harmoniques pour obtenir le son souhaité, dans la synthèse additive, de nouvelles harmoniques sont ajoutées pour configurer le son final. Ici, au lieu d’utiliser la métaphore du sculpteur qui élimine de la matière du bloc de marbre pour obtenir la forme désirée, l’image se rapprocherait davantage du potier qui ajoute de plus en plus d’argile pour fabriquer et façonner son vase.
Dans les sections précédentes, nous avons souligné deux aspects importants :
- Une onde sinusoïdale ne contient aucune harmonique
- Tout son, qu’il soit naturel ou artificiel, peut être réduit à un ensemble ou à une combinaison d’ondes sinusoïdales à différentes fréquences et amplitudes.
La « construction » du son en synthèse additive consiste donc à additionner un certain nombre de formes d’ondes sinusoïdales à différentes amplitudes et fréquences pour configurer le timbre. Prenons un exemple : la création d’une forme d’onde en dents de scie à partir d’ondes sinusoïdales. En partant d’une fréquence de base de 500 Hz, si nous ajoutons une première harmonique (une octave plus élevée, 500 Hz x 2 = 1 kHz, à une amplitude plus faible), et une deuxième harmonique (500 Hz x 3 = 1,5 kHz, à une amplitude encore plus faible), la forme d’onde résultante commence à ressembler à une dent de scie.

Si nous utilisons suffisamment de partiels, le résultat sera une forme d’onde en dents de scie précise. En théorie, il est possible de reproduire n’importe quel son en utilisant cette technique, bien que cela puisse nécessiter une série extrêmement longue d’harmoniques pour recréer exactement un son particulier. Cependant, ce schéma présente des difficultés supplémentaires, notamment une plus grande complexité de programmation et des résultats moins prévisibles par rapport à la synthèse soustractive. Dans cette dernière, il est relativement facile et rapide, avec un peu de pratique, de prédire comment la modification d’un paramètre (l’intensité du filtre, la fréquence de coupure, la forme d’onde de l’oscillateur, etc.) affectera le son final, et il est possible de tenter de construire un certain son sans avoir besoin de connaître préalablement la structure de ses harmoniques. En revanche, en synthèse additive, si notre objectif est de reproduire un son spécifique, nous devons connaître préalablement la structure des harmoniques. C’est probablement l’une des principales raisons pour lesquelles il y a un nombre assez limité de synthétiseurs utilisant la synthèse additive.
De manière assez surprenante, les premiers synthétiseurs de synthèse additive peuvent être considérés comme les premiers orgues. Dans un orgue à tuyaux, comme ceux que l’on peut trouver dans certaines églises, l’air qui circule à travers le tuyau produit une vibration audible, similaire au son d’une flûte. En utilisant les pédales, le joueur peut contrôler les tuyaux à travers lesquels l’air circule, changeant ainsi les harmoniques et modifiant le timbre. Dans un orgue électrique, comme le Hammond, créé dans les années 30 du XXe siècle comme alternative aux orgues à tuyaux (très lourds, encombrants et fragiles), le timbre est configuré à partir de plusieurs générateurs électriques (dynamos) qui produisent des formes d’ondes sinusoïdales à différentes fréquences (9 par note). L’amplitude ou l’intensité de chaque onde (harmonique) est contrôlée par des potentiomètres sous la forme de tirettes, permettant de sélectionner une valeur minimale de 0 (éteint) jusqu’à 8 (niveau d’amplitude maximum).
Parmi les synthétiseurs modernes, la synthèse additive est utilisée par des modèles tels que la série K5 ou K5000 de Kawai, bien que ce dernier modèle combine la synthèse additive (avec jusqu’à 64 partiels) avec la synthèse par table d’ondes. De plus, il dispose de différents types de filtres, d’oscillateurs basse fréquence et d’autres éléments pour permettre une édition sonore encore plus puissante.
La synthèse par modulation de fréquence (FM)
La synthèse par modulation de fréquence (souvent simplement appelée « FM ») a une histoire assez curieuse. Elle a été découverte presque par hasard dans les années 60 par John Chowning, un chercheur de l’Université de Stanford, alors qu’il travaillait sur des techniques de vibrato. Plus tard, au milieu des années 70, lorsque Chowning et ses collaborateurs avaient déjà un modèle avancé de synthèse FM, adapté à une exploitation commerciale par les fabricants de synthétiseurs, ils ont découvert que les principales entreprises de synthétiseurs américaines n’étaient pas intéressées par cette technologie et ne voyaient pas son potentiel.
Dans un geste assez désespéré, Chowning a proposé la technologie à la marque japonaise Yamaha, qui était très intéressée et a signé un accord de licence pour l’exploitation exclusive du brevet (qui était la propriété de l’Université de Stanford). Au cours des années suivantes, Yamaha a utilisé cette technologie dans d’innombrables produits, tant des synthétiseurs professionnels que des claviers domestiques, avec un énorme succès commercial, ce qui a rapporté d’importants bénéfices à l’Université de Stanford, le brevet étant, jusqu’à son expiration en 1995, celui qui a généré le plus de revenus de toute l’histoire de l’institution. De nos jours, plusieurs modèles de synthétiseurs incluent la FM parmi leurs méthodes de synthèse.
Le fonctionnement théorique de la modulation de fréquence est en réalité très similaire au vibrato, d’où le contexte dans lequel elle a été découverte. Le vibrato consiste en une variation cyclique de la fréquence de l’onde, ce qui modifie légèrement (généralement) sa hauteur autour d’une certaine fréquence de base à une certaine vitesse, créant ainsi cette sensation de « vibration ». Supposons qu’une violoniste joue un La à une fréquence de 440,0 Hz. Lorsqu’elle applique le vibrato, elle le fait en déplaçant légèrement et de manière cyclique le doigt qui appuie sur la corde (pendant que cette corde est jouée avec l’archet par l’autre main). Ce mouvement fait varier légèrement la longueur de la corde, ce qui détermine la hauteur (fréquence), la rendant cycliquement un peu plus longue et plus courte, ce qui abaisse et élève la hauteur (fréquence) du son.
Dans un synthétiseur, l’effet de vibrato peut être obtenu en utilisant un oscillateur basse fréquence (LFO), qui affecte le signal de l’oscillateur principal (celui qui produit la fréquence audible). L’onde générée par l’oscillateur est généralement appelée le porteur, tandis que le signal du LFO est appelé le modulateur. La fréquence du porteur est fixée à une certaine valeur (par exemple, une onde sinusoïdale à 440,0 Hz). Le signal du modulateur (généralement une onde sinusoïdale ou triangulaire lorsqu’on essaie de produire un vibrato) est appliqué à celui de l’oscillateur, le modifiant de manière cyclique, selon l’amplitude (intensité) du modulateur et la fréquence déterminée (cycles par seconde). En jouant avec les paramètres d’amplitude et de fréquence du modulateur, l’utilisateur peut contrôler la profondeur et la vitesse de l’effet de vibrato.
Le point crucial pour comprendre la synthèse FM est le suivant : normalement, les fréquences utilisées pour créer le vibrato sont très basses (entre 10 et 15 Hz, en dessous de la plage de fréquences audibles), car c’est la seule façon de percevoir l’effet comme tel. Mais que se passe-t-il lorsque la fréquence du modulateur est augmentée et tombe dans la plage des fréquences audibles ? Il en résulte que l’onde résultante de l’interaction entre le porteur et le modulateur est (ou peut être) totalement différente, créant de nouvelles formes d’ondes et harmoniques (en somme, de nouveaux sons) totalement différents des formes d’onde d’origine. L’effet de la modulation dépend, comme on peut l’imaginer, de l’amplitude du modulateur (appelée ici « indice de modulation ») et de la fréquence appliquée au porteur. En résumé, la synthèse FM n’est rien d’autre qu’un vibrato très rapide.
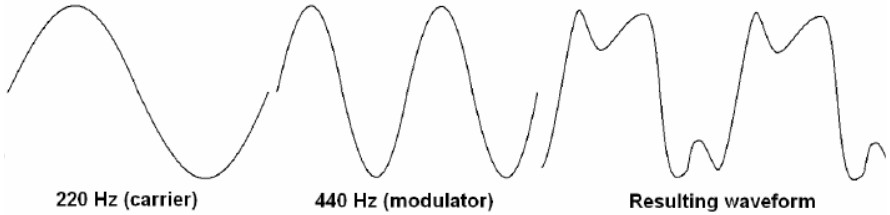
La synthèse par modulation de fréquence (FM) permet de générer des sons impossibles à créer avec les synthétiseurs analogiques à synthèse soustractive alors couramment utilisés. En revanche, il est pratiquement impossible d’émuler l’effet d’un filtre en utilisant la synthèse FM. Néanmoins, ce type de synthèse est réputé pour être difficile à programmer et produire des résultats assez imprévisibles, à moins que l’on ait une compréhension claire des fondements mathématiques de la modulation de fréquence (les résultats des interactions entre différentes ondes par le biais de la synthèse FM peuvent être déterminés à l’aide des fonctions de Bessel). En règle générale, les fréquences du porteur et du modulateur doivent être des multiples pour créer des sons harmoniques, car sinon, les sons résultants sont assez dissonants et « métalliques ».
Bien qu’il n’y ait pas d’obstacle à l’utilisation de la modulation de fréquence avec des formes d’ondes générées par des oscillateurs analogiques, généralement ces oscillateurs ne sont ni suffisamment précis ni stables pour utiliser ce type de synthèse de manière satisfaisante, car elle est très sensible aux petites variations. C’est la principale raison pour laquelle la synthèse FM a été presque exclusivement utilisée (et exclusivement dans le cas de Yamaha) dans les synthétiseurs numériques, comme la célèbre série DX du début et du milieu des années 80.
Dans la nomenclature de Yamaha, la synthèse est réalisée à l’aide de différents opérateurs, qui peuvent interagir de différentes manières (routes ou algorithmes). Yamaha a développé des synthétiseurs basés sur deux, quatre et six opérateurs. Un opérateur est un « bloc » composé d’un oscillateur (qui produit uniquement des formes d’onde sinusoïdales), de ses enveloppes correspondantes et d’amplificateurs. Chaque oscillateur (opérateur) peut se comporter comme un porteur ou un modulateur, et les signaux des porteurs (s’il y en a plus d’un) sont mélangés pour former le son final. De plus, il n’y a pas d’obstacle à ce qu’un modulateur module un autre modulateur. Par conséquent, à titre d’exemple, dans un schéma à six opérateurs, les opérateurs 1 et 2 peuvent agir comme porteurs, tandis que l’opérateur 3 peut moduler l’opérateur 1, et l’opérateur 4 peut moduler l’opérateur 5, qui module à son tour l’opérateur 6, qui module à son tour l’opérateur 2 (porteur). Ensuite, les signaux des opérateurs 1 et 2 sont mélangés et envoyés à la sortie audio du synthétiseur. Cela donne une idée de la puissance et de la flexibilité de la synthèse FM.
La synthèse de table d’ondes (wavetable synthesis)
La synthèse de table d’ondes repose sur le même principe : au lieu d’utiliser des oscillateurs qui génèrent des formes d’onde simples, elle utilise un circuit électronique qui reproduit certains échantillons sonores numérisés à différentes fréquences en fonction des notes à jouer. De cette manière, des niveaux élevés de réalisme peuvent être atteints, ce qui était auparavant impossible à réaliser. Cependant, tout n’est pas que positif, comme nous allons le voir.
Un inconvénient important de cette technologie est qu’elle nécessite beaucoup de mémoire pour stocker les échantillons sonores. De nos jours, ce n’est pratiquement plus un problème, mais cela posait un gros problème au début des synthétiseurs numériques à table d’ondes (au milieu et à la fin des années 80). À cette époque, la mémoire était très coûteuse (et aussi très lente par rapport à la technologie actuelle), ce qui fait que les synthétiseurs avaient généralement peu d’échantillons, généralement de courte durée et de faible qualité, dans le but de réduire les coûts (ou du moins, de ne pas augmenter le prix final).
Dans certains cas, comme le Kawai K1 ou les synthétiseurs de la série D de Roland, seule la partie d’attaque du son (et peut-être la décroissance) était échantillonnée, le reste du son étant réalisé à l’aide de la synthèse « traditionnelle » (soutien, relâchement), ou il y avait une utilisation intensive de boucles, où la partie de soutien était constituée de la répétition continue de certaines parties de la même forme d’onde échantillonnée. La qualité des échantillons n’était pas non plus très élevée au départ. La quantité de mémoire utilisée par un échantillon sonore dépend directement de trois facteurs principaux : la résolution, la fréquence et la longueur.
Les deux premiers éléments déterminent la qualité sonore globale. Les premiers synthétiseurs numériques à table d’ondes avaient des échantillons de résolution 8 bits (comme l’Ensoniq Mirage) ou 12 bits (comme la série SY de Yamaha) à des fréquences d’échantillonnage assez faibles (généralement pas plus de 22 kHz). La résolution, la fréquence d’échantillonnage et la longueur de l’échantillon ont augmenté au fil des ans grâce à l’évolution et à la baisse des prix des composants électroniques (en particulier la mémoire).
Un autre inconvénient de cette technologie au départ, qui a depuis été surmonté, est qu’une forme d’onde numérisée est beaucoup plus difficile à manipuler que le signal d’un simple oscillateur, car elle nécessite des capacités de calcul beaucoup plus importantes. Pour cette raison, certains premiers modèles de synthèse de table d’ondes avaient des structures de synthèse très simples, de sorte qu’ils n’étaient pas en mesure de modifier de manière significative le son (par rapport aux synthétiseurs analogiques ou numériques basés sur la synthèse soustractive).
Il était assez courant dans les années 80 qu’ils n’aient même pas de filtre (c’est le cas, par exemple, du Kawai K1 ou de la série U de Roland), car cela impliquerait de réaliser plusieurs calculs en temps réel, de sorte que les seules « modifications » possibles étaient l’ajustement du vibrato (fréquence de la forme d’onde) et l’enveloppe de l’amplificateur (ADSR). Plus tard, grâce à l’augmentation de la vitesse et de la capacité des microprocesseurs et des composants numériques en général, tous les éléments habituels de la synthèse soustractive ont été ajoutés (filtres, LFO, plusieurs oscillateurs simultanés, etc.), de sorte que les synthétiseurs à table d’ondes d’aujourd’hui peuvent être considérés comme l’évolution « naturelle » des anciens synthétiseurs à synthèse soustractive, la différence la plus importante étant la possibilité d’utiliser plusieurs centaines, voire des milliers, de formes d’onde complexes au lieu d’un petit ensemble de formes d’onde de base.
Un autre aspect négatif de cette technologie est que le son peut être assez statique et artificiel. Si l’on prend un instrument acoustique, tel qu’un violon, on constate que ses capacités timbriques et expressives sont énormes, en fonction de la technique de jeu (legato, marcato, etc.), de l’intensité (piano, forte, fortissimo, etc.), de la vitesse (plus lente ou plus rapide), etc. En revanche, un échantillon numérisé est simplement un enregistrement qui sonne toujours de la même manière. Si, par exemple, on prend un échantillon d’une touche de piano (l’octave centrale « Do », par exemple) et qu’on le joue à différentes fréquences pour construire toute la gamme (des octaves les plus basses aux plus élevées), on constate que plus on s’éloigne de la touche d’origine, plus le son devient artificiel et moins proche du son de l’instrument original (l’octave centrale « Do » sonnera presque comme un vrai piano, mais un « Do » situé 2 octaves plus bas sera très différent, car les harmoniques de l’instrument original changent).
Cela oblige donc à prendre plusieurs échantillons du même instrument à différents intervalles de hauteur (avec l’utilisation correspondante de la mémoire), afin d’obtenir un certain niveau de cohérence sonore sur toute la gamme. Mais cela ne suffit pas. Dans la plupart des instruments acoustiques, les différences d’amplitude (intensité) impliquent également des changements timbriques. Le son d’une trompette, par exemple, est différent lorsqu’il est joué doucement (plus doux) ou lorsqu’il est joué à pleine puissance (plus brillant). Si l’on n’a qu’un seul échantillon, tout ce que l’on peut faire, c’est de le jouer à différents niveaux de volume, mais on ne pourra pas émuler la dynamique réelle de l’instrument. Pour tenter de résoudre cette lacune et de produire un son plus convaincant, les synthétiseurs utilisent différentes techniques. L’une d’entre elles consiste à utiliser un filtre (si le synthétiseur en est équipé).
Avec un filtre passe-bas, lorsque le son est joué doucement, la fréquence de coupure est plus basse, coupant les fréquences plus élevées et rendant le son plus doux, tandis que lorsque l’intensité augmente, la fréquence de coupure augmente également et le son devient plus brillant. Une autre technique (non incompatible avec la précédente) est la commutation de vélocité. Cela consiste à obtenir différents échantillons de la source sonore d’origine à différents niveaux d’intensité (amplitude) (par exemple, un échantillon pris lorsque l’instrument est joué doucement et un autre lorsque l’instrument est joué fort) et à utiliser l’un ou l’autre en fonction de l’intensité à laquelle le synthétiseur est joué : lorsque l’intensité est inférieure à une certaine valeur, l’échantillon de piano sera utilisé, et pour les intensités supérieures à cette valeur, l’échantillon de forte sera utilisé.
La forme la plus basique de commutation de vélocité consiste à utiliser seulement deux niveaux différents, mais la plupart des synthétiseurs actuels peuvent offrir trois niveaux ou plus, ce qui permet des transitions plus subtiles et plus douces.
Si l’on ajoute également un filtre, des transitions très douces et graduelles peuvent être obtenues, ce qui conduit à un résultat final très proche de l’instrument acoustique d’origine. L’évolution des prix de la mémoire et de la technologie a fait que les synthétiseurs utilisent progressivement plus d’échantillons, qui sont également plus longs et de meilleure qualité, ce qui se traduit par des améliorations remarquables en termes de réalisme et de qualité sonore. Pour prendre un exemple, un synthétiseur moderne comme le Roland Fantom X (sorti en 2004) utilise, pour la banque de sons de piano acoustique, des échantillons individuels de chacune des 88 touches du piano à quatre niveaux différents (piano, mezzoforte, forte et fortissimo), ce qui donne un total de plus de 700 échantillons pour cette seule banque de sons. Cela, combiné à une structure de synthèse avancée, le rend difficile à distinguer de l’instrument réel, même pour un musicien.
La synthèse par modélisation physique
La synthèse par modélisation physique est une méthode de synthèse sonore qui vise à reproduire le comportement physique des ondes sonores d’un instrument de musique, en utilisant des équations et des algorithmes pour émuler les caractéristiques physiques de la source sonore. Cette méthode permet de créer des simulations précises d’instruments de musique, qu’ils soient réels ou inventés. Elle prend en compte des variables telles que la taille, la forme, les matériaux de construction, la technique de jeu, etc.
La synthèse par modélisation physique permet de reproduire des instruments de manière plus précise que d’autres méthodes de synthèse sonore. Elle est souvent appelée « synthèse acoustique virtuelle » car elle vise à recréer de manière réaliste le son des instruments acoustiques. Cette technologie permet également d’introduire de légères imperfections pour rendre les simulations plus convaincantes, simulant ainsi les caractéristiques des vrais instruments acoustiques.
Cependant, cette technologie requiert une grande puissance de traitement, ce qui explique pourquoi elle n’a été mise en œuvre dans des synthétiseurs commerciaux qu’à partir des années 1990. Même à cette époque, la plupart des premiers modèles étaient strictement monophoniques ou biphoniques, alors que les synthétiseurs polyphoniques à table d’ondes de 32 et 64 voix étaient très courants.
Yamaha a été l’un des premiers fabricants à proposer cette technologie, grâce à un accord signé en 1989 avec l’Université Stanford. Le premier modèle commercialisé a été le Yamaha VL-1 en 1994.
Une particularité surprenante de cette technologie de synthèse est qu’elle a été couronnée de succès non seulement dans l’émulation d’instruments acoustiques, mais aussi dans la recréation virtuelle des classiques synthétiseurs analogiques de la synthèse soustractive. La précision et la stabilité accrues de la technologie numérique ont permis de reproduire fidèlement les caractéristiques sonores des anciens synthétiseurs analogiques. Aujourd’hui, de nombreux synthétiseurs utilisent la synthèse par modélisation physique pour reproduire les caractéristiques et le comportement de la technologie analogique, afin de créer le son le plus proche possible des synthétiseurs analogiques classiques grâce à la technologie numérique.
C’est incroyable de voir comment les différents types de synthèse influencent la création sonore. La synthèse soustractive, avec sa méthode d’élimination des harmoniques, est un incontournable pour les sons classiques. La synthèse additive, bien que plus complexe, permet une précision inégalée. La synthèse par modulation de fréquence (FM) a révolutionné les années 80 avec des sons uniques, tandis que la synthèse par table d’ondes offre une grande variété grâce aux échantillons numérisés. Enfin, la synthèse par modélisation physique recrée avec réalisme les instruments acoustiques, ouvrant de nouvelles possibilités créatives.
Dans les années 1980, Yamaha a révolutionné le monde des synthétiseurs avec la série DX, notamment le DX7, en utilisant la synthèse par modulation de fréquence (FM). Avant son lancement, les principaux fabricants américains de synthétiseurs avaient refusé d’acheter la technologie FM, ne voyant pas son potentiel. Yamaha, en revanche, a rapidement saisi l’opportunité. Résultat : le DX7 est devenu l’un des synthétiseurs les plus vendus de tous les temps, utilisé par des artistes comme Phil Collins, Michael Jackson et Prince. Cette adoption massive de la FM a non seulement changé la musique pop de l’époque mais a aussi rapporté d’importants bénéfices à l’Université de Stanford, propriétaire du brevet.